
Greta Tuckute
Email concatenate 'gretatu' with '@mit.edu'Scholar Greta Tuckute
GitHub gretatuckute
Twitter/X @GretaTuckute
Bluesky gretatuckute.bsky.social
Hi, I am Greta. Thank you for visiting my page. I study how language is implemented in biological and artificial systems. My work falls in the intersection of neuroscience, artificial intelligence (AI) and cognitive science. I graduated from MIT's Department of Brain and Cognitive Sciences working with Dr. Ev Fedorenko in December 2024 (continuing as a post-doc until summer 2025). I am originally from Lithuania, and I completed my BSc and MSc degrees at KU/DTU with coursework and research at MIT/CALTECH/Hokkaido University. When I don't do science, I enjoy photography, rowing, mornings, and magic realism books.
News & Talks
Research Updates
A two-dimensional space of linguistic representations shared across individuals

Humans learn and use language in diverse ways, yet all typically developing individuals acquire at least one language
and use it to communicate complex ideas. This fundamental ability raises a key question: Which dimensions of language
processing are shared across brains, and how are these dimensions organized in the human cortex?
In this work, we show that voxel responses during comprehension are organized along two main axes: processing difficulty and meaning abstractness—
revealing an interpretable, topographic representational basis for language processing shared across individuals.
Our paper is organized according to three key questions:
First, how many components of language are shared across individuals?
We applied decomposition methods to 7T fMRI data from 8 participants listening to 200 linguistically diverse sentences.
The resulting components—"Sentence PCs"—indicate how much each sentence drives variance along a given direction in voxel space.
Using a stringent leave-one-participant-out cross-validation scheme, we find that two components (denoted as "Sentence PCs")
successfully generalize across participants, together accounting for ~32% of the explainable variance in brain responses to sentences.
These two Sentence PCs show high predictivity in or proximal to frontal and temporal language areas—with one notable exception: predictivity in the left ventral stream,
a part of the brain primarily associated with high-level vision (in this experiment, participants listened to the sentences).
Second, what characterizes the two Sentence PCs?
We collected a set of linguistic/semantic features and ran targeted experiments to characterize the Sentence PCs.
Based on these analyses, our candidate explanations are that PC 1 corresponds to processing difficulty and PC 2 to meaning abstractness.
Specifically: Sentences with high loadings on Sentence PC 1 require more effort to read, are more surprising, and are perceived as less frequent.
Sentences with high loadings on Sentence PC 2 are hard to visualize and convey abstract content.
How are the components spatially organized?
We analyzed the voxel-wise Sentence PC weights and found that the Sentence PCs are systematically distributed
across the lateral and ventral surface, forming a large-scale topography that is systematic across individuals.
Most voxels within the five frontal and temporal language areas exhibit preference for “hard-to-process/abstract” sentences.
But critically, finer-grain substructure exists within and across areas: for instance, the temporal areas are more tuned to abstract meanings compared to the frontal ones.
Finally, well-predicted voxels in the ventral stream prefer sentences that are easy to visualize.
Thus, the two Sentence PCs' predictions appear meaningfully situated within the broader topography of the brain—
with tuning for concrete, visualizable sentences in brain areas associated with vision.
In sum, we identified two shared components—processing difficulty and meaning abstractness—that exhibit systematic topography across frontal and temporal areas, extending into the ventral visual stream.
This low-dimensional subspace may serve as a representational scaffold for meaning extraction.
Tuckute, G., Lee, E.J., Ou, Y., Fedorenko, E., Kay, K. (2025): A two-dimensional space of linguistic representations shared across individuals, BioRxiv, doi: https://doi.org/10.1101/2025.05.21.655330
Model connectomes: A generational approach to data-efficient language models
Biological neural networks are shaped both by evolution across generations and by individual learning within an organism’s lifetime,
whereas standard artificial neural networks undergo a single, large training procedure without inherited constraints.
In this preliminary work, we propose a framework that incorporates this crucial generational dimension—an "outer loop"
of evolution that shapes the "inner loop" of learning—so that artificial networks better mirror the effects of evolution
and individual learning in biological organisms.
Focusing on language, we train a model that inherits a "model connectome" from the outer evolution loop before
exposing it to a developmental-scale corpus of 100M tokens.
Compared with two closely matched control model (one with a random connectome and another without any connectome),
we show that the connectome model performs better or on par on
natural language processing tasks as well as alignment to human behavior and brain data
These findings suggest that a model connectome serves as an efficient prior for learning in low-data regimes –
narrowing the gap between single-generation artificial models and biologically evolved neural networks.
Kotar*, K. & Tuckute*, G. (2025): Model Connectomes: A Generational Approach to Data-Efficient Language Models, International Conference on Learning Representations (ICLR 2025), Re-Align Workshop, doi: https://www.arxiv.org/abs/2504.21047
Code associated with project can be found here.
A framework for efficiently generating standardized, child-friendly audiovisual stimuli
In my PhD, I was very excited about developing condition-rich data collection paradigms for language, in particular, for sentence-level processing. In these paradigms, the core goal is to measure reliable brain responses to a large number of stimuli (sentences) in a small sample of individuals (e.g., Tuckute et al., 2024), which, for instance allows us to ask how the language network is tuned to various stimulus properties. In an ongoing project, we are extending this condition-rich neuroimaging approach to children (led by Halie Olson). Working with children introduces new challenges, such as distractibility, limited attention span, motivation and willingness to engage in the experimental context. So, stimuli need to be engaging (and not at the expense of experimental controls!).
Read more
In this work, we developed an automated pipeline for generating audiovisual stimuli targeted at neuroimaging experiments with children.
The pipeline consists of two main components: the first generates auditory stimuli from text, and the second
creates video stimuli in which an animated character says the stimuli out loud.
highlights the value of automated tools in developing large sets of standardized, engaging, and well-controlled
stimuli--making condition-rich paradigms more feasible in developmental populations.
Santi, B., Soza, M., Tuckute, G., Sathe, A., Fedorenko, E., Olson, H. (2025): An Automated Pipeline for Efficiently Generating Standardized, Child-friendly Audiovisual Stimuli, PsyArXiv, doi: https://doi.org/10.31234/osf.io/8gcn7_v1
Code associated with project can be found here.
Mulitlingual language models reveal shared brain responses across 21 languages
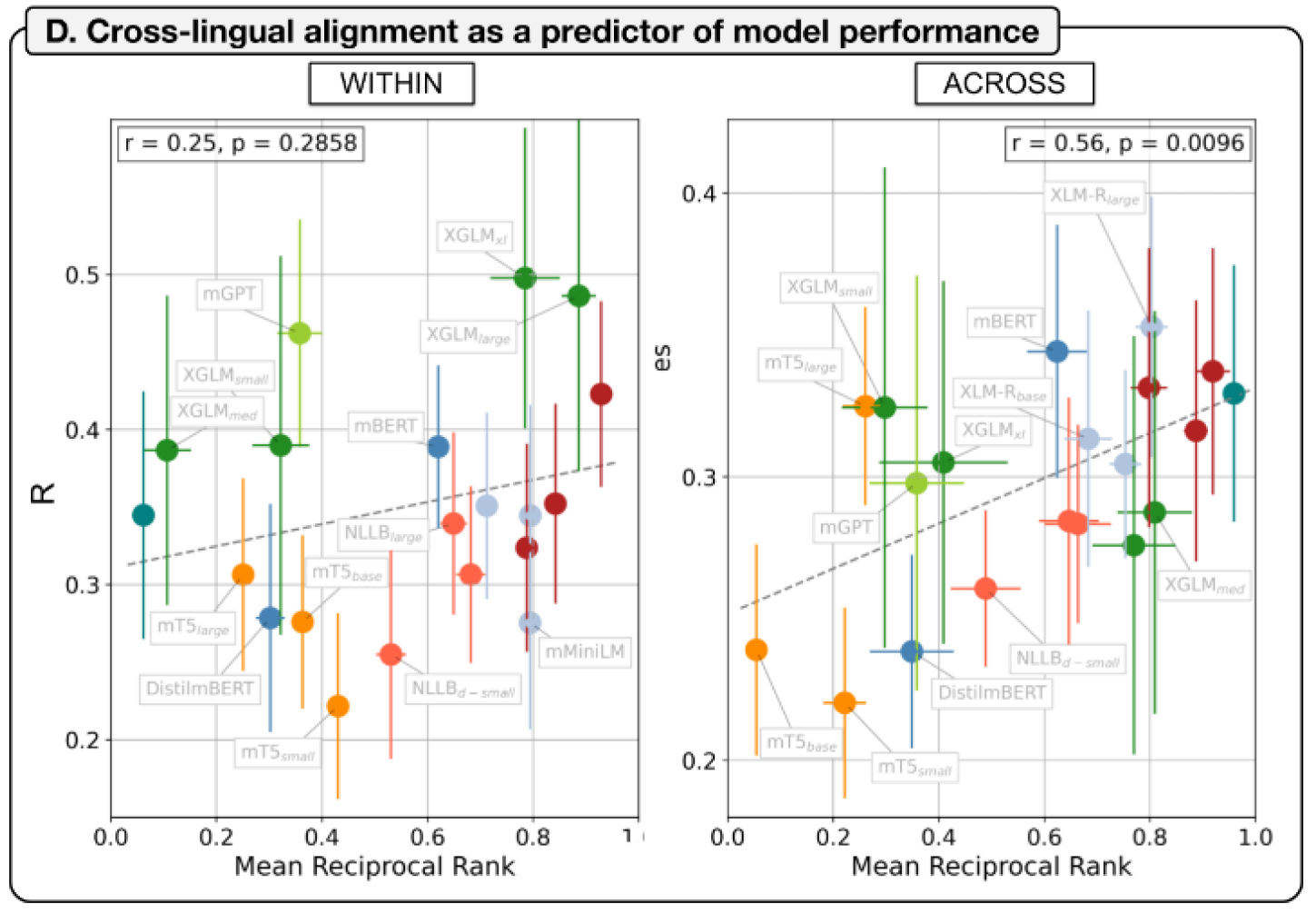
How does the human brain process the rich variety of languages?
In this work, we broadly tackle this question by leveraging recent advances in multilingual large language models (MLLMs)
to investigate brain representations across different languages (21 in total!).
We combine existing (12 languages, 24 participants) and newly collected fMRI data (9 languages, 27 participants)
to first ask whether model-brain alignment generalizes across typologically diverse languages.
We evaluated 20 multilingual LMs with different architectures and training objectives, and show that these models
have enough of a shared inter-language component so enable zero-shot cross-linguistic generalization:
you can train a MLLM-to-brain mapping model using English + Lithuanian and then predict brain responses to Norwegian.
Next, we asked: What kind of information is shared across languages in the brain?
Our findings point to semantics (rather than form-level properties of language). We ruled out shallow form-level
predictors (word length and frequency) and found no evidence that formal linguistic similarity (e.g., syntax or phonology)
explained cross-linguistic generalization. These findings suggest that shared
brain responses across languages are primarily driven by linguistic meaning.
Altogether, our findings provide strong evidence for a shared, meaning-based component in how the human brain processes
diverse languages.
de Varda, A., Malik-Moraleda, S., Tuckute, G., Fedorenko, E. (2025): Multilingual language models reveal shared brain responses across 21 languages, bioRxiv, doi: https://doi.org/10.1101/2025.02.01.636044
Code and data associated with project can be found here.
Identifying causally important LLM units for linguistic tasks using neuroscience approaches
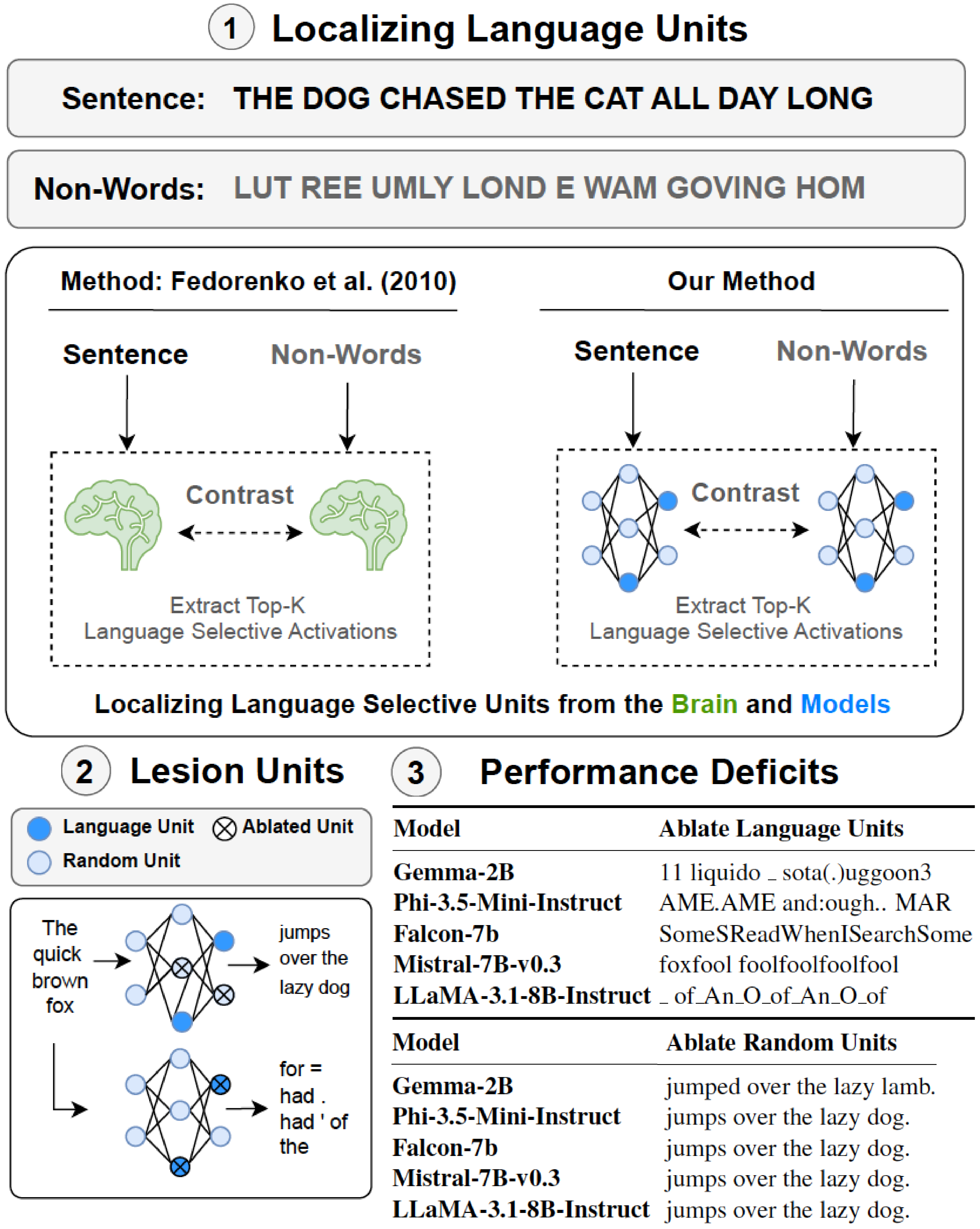
Isolating LLM units that are causally important for various behaviors is of key interest to both
computer scientists and neuroscientists. In this paper, we leverage neuroscience methods to identify
"language network" units in LLMs and subsequently asses their causal role in next-word prediction and various
linguistic benchmarks, as well as their similarity to human brain responses during language processing.
This work takes a step towards mapping out the functional organization of LLMs using approaches that have been very
succesful in neuroscience, highlighting the emergence of causally task-relevant LLM units that in some ways parallel
that brain's language network.
Inspired by cognitive neuroscience (e.g.,
Fedorenko et al., 2010),
we identify "language network" units in 18 popular LLMs by isolating the units that
respond most strongly to sentences compared to lists of non-words.
To evaluate the causal role of these units in behavior, we lesion the "language network" units. First,
we demonstrate that lesioning "language network" units--and not the same number of random units--completely
disrups the LLMs' ability to predict the next word (see table left). Notable, these ablations involve
just 1% of the LLMs' units.
Second, we evaluate the LLMs' ability to perform various linguistic tasks such
as question-answering (GLUE), acceptability judgments (BLiMP), and judging syntax (SyntaxGym). We show that
ablating "language network" units leads to large performance drops (up to 40%), while lesioning random units
has ~no impact.
Third, we ask whether these "language network" units are similar to human brain responses.
Prior work comparing LLMs to brain data typically uses units from a full LLM layers or across the whole LLM,
without isolating functional subcomponents. In this work, we first show that the "language network" units reproduce
empirical findings about the human language network such as a higher response to Sentences than
unconnected words (W), Jabberwocky (J) and non-words in held-out materials (such as in several
studies, e.g., Fedorenko et al., 2010). Next, we show that the activation patterns of "language network" units
are more aligned with human brain responses than randomly sampled units.
This work moves toward mapping the internal organization of LLMs and understanding representational correspondence
between brain regions and LLMs in terms of shared, behaviorally relevant function.
Finally, we demonstrate the feasibility of applying the neuroscientific approach to identify relevant LLM units in
other domains, such as within structured reasoning and social inference.
AlKhamissi, B., Tuckute, G., Bosselut^, A., Schrimpf^, M. (2025): The LLM Language Network: A Neuroscientific Approach for Identifying Causally Task-Relevant Units,
Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL 2025; *Oral),
doi: https://doi.org/10.48550/arXiv.2411.02280
AlKhamissi, B., Tuckute, G., Bosselut^, A., Schrimpf^, M. (2024): Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network, arXiv, doi:
https://doi.org/10.48550/arXiv.2406.15109
Code associated with project can be found here.
Localizing the human language network in ~3.5 minutes using speeded reading
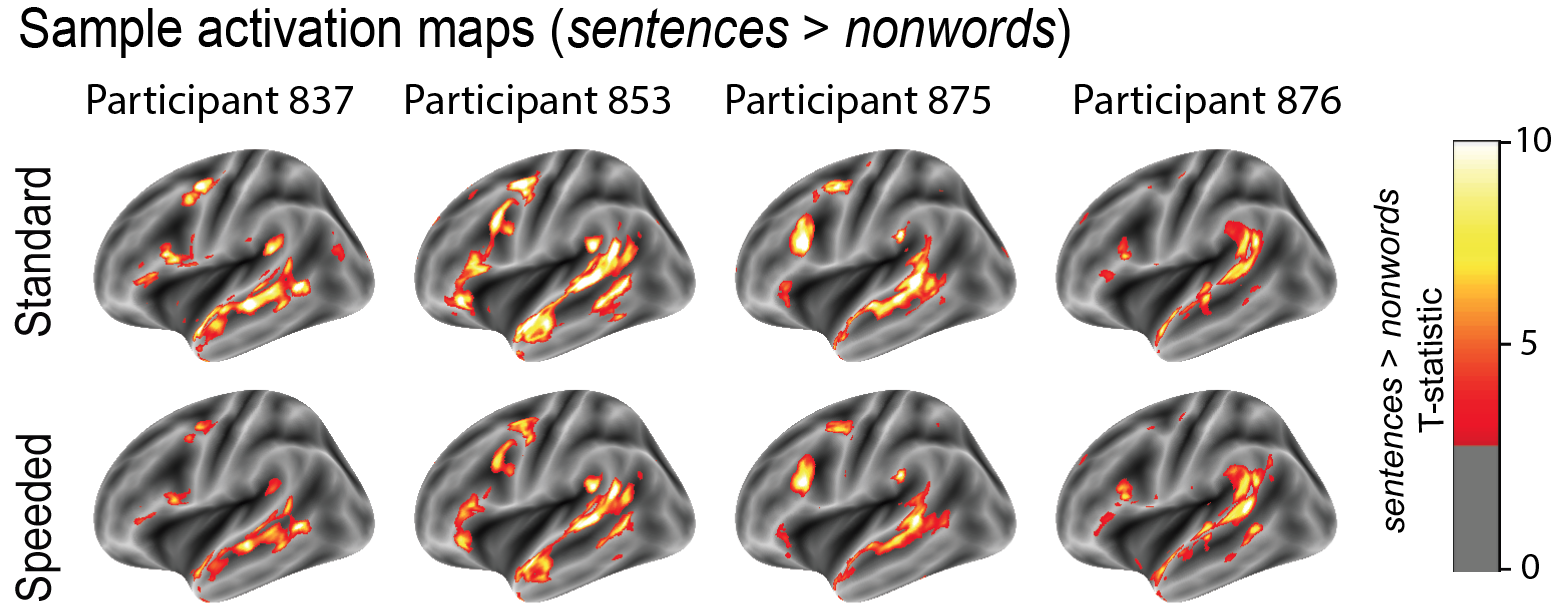
Functional "localizers" aim to isolate a (set of) brain regions that support a cognitive process (such as face processing, or language processing) in individual participants. It is challenging to rely on brain anatomy alone, because individuals have different brains. Hence, localizers are a powerful way to isolate a cognitive process in the brain, but one concern is that they take time away from the critical experiment. One ongoing effort in cognitive neuroscience is to make localizers as efficient as possible. This is what we do here.
Read more
We present a speeded version of a widely used localizer (Fedorenko et al., 2010) for the language
network (for a review on the language network, see
Fedorenko et al., 2024).
This localizer uses a reading task contrasting sentences and sequences of nonwords. However,
our localizer is faster as we present each word/nonword for 200ms instead of 450ms.
In the paper, we first investigated whether the speeded localizer version can reliably localize
language-responsive areas in individual participants (n=24). The brief answer is yes. First,
we looked at the voxel-level activation maps, and found that the speeded localizer elicited highly
similar activation topographies as the standard localizer (Fedorenko et al., 2010). Next, we
investigated the BOLD response magnitudes and found that the speeded localizer elicited a robust
response to sentences, with an even greater sentences > nonwords effect size than the standard
localizer. Second, we asked whether increased processing difficulty due to speeded reading affects
neural responses in the language network and/or elsewhere in the brain. We focused on the Multiple
Demand (MD) network, sensitive to cognitive effort across various domains and in some cases of
effortful language comprehension. It is an open question how the MD network (and other brain
regions) contributes to language processing during different kinds of effortful linguistic
processing. We found that the MD network responded ~43% more strongly during speeded sentence
reading vs. standard sentence reading (compared to a ~16% increase in the language network to
speeded reading). Moreover, we did not observe a nonwords > sentences effect in the speeded
localizer, compared to the standard one. Hence, speeded reading was more effortful than slower
reading, and this cost loaded largely onto the domain-general Multiple Demand (MD) network
(only minimally manifesting in the language network and not affecting the ability to localize
language areas).
We hope that this language localizer will be useful to researchers when time is of essence
(this localizer was developed when we were trying to cram hundreds of sentences into a single
fMRI session a few years ago). It should work well with any proficient readers.
Tuckute*, G., Lee*, E.J., Sathe, A., Fedorenko, E. (2024): A 3.5-minute-long reading-based fMRI localizer
for the language network, bioRxiv, doi:
https://doi.org/10.1101/2024.07.02.601683
.
The associated code to run the speeded language localizer (and analyses) can be found
here.
Brain-like topographic organization in Transformer language models
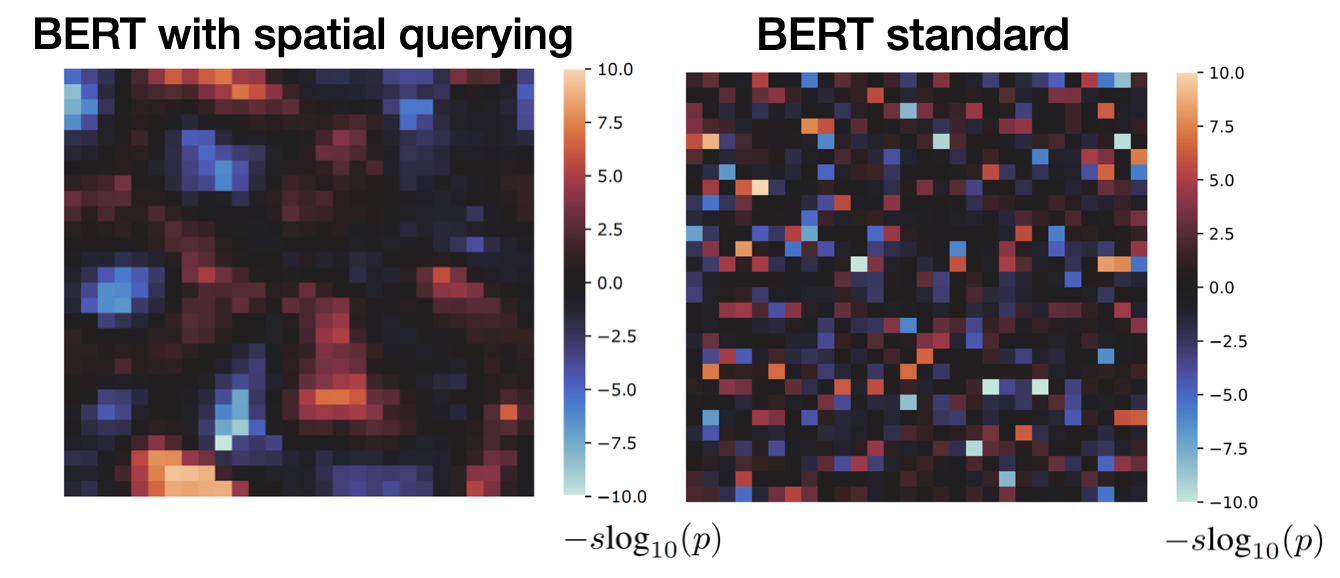
Large language models (LLMs) fundamentally differ from the human language system. One notable
difference is that biological brains are spatially organized, while current LLMs are not. In
this work, we attack this issue, and propose a topographic LLM ("Topoformer")--a critical step
towards developing more biologically plausible LLMs.
The Topoformer model uses a novel form of self-attention, converting standard neuron vectors
into 2D spatial grids. Spatial variants of querying and reweighting operations give rise to
topographic organization of representations within the self-attention layer. We first trained
a toy Topoformer model on a supervised sentiment task (rating movie reviews as being positive
or negative), and we found that the model learned selectivity for positive versus negative
sentiment in the layers of the Topoformer model.
Next, we scaled up our approach, and trained
a BERT Transformer model with the topographical motifs, on masked word prediction. The
performance of the Topoformer-BERT model was similar to that of a non-topograhical BERT across
several linguistic benchmarks. Hence, topography does not impede function (nor enhance it).
Finally, we asked whether the topographic organization in the Topoformer-BERT model
corresponded to that of the human language system. We found that the language responses in the
human brain were topographic ("smooth"/"patchy"), and critically, that dimensions between
Topoformer-BERT and the brain could be aligned.
This work provides a critical step towards developing more biologically plausible LLMs.
BinHuraib, T.O.A, Tuckute, G., Blauch, N. (2024): Topoformer: brain-like topographic organization
in Transformer language models through spatial querying and reweighting, ICLR Re-Align Workshop.
The project website and code can be found
here.
Review on language in brains, minds, and machines

Thrilled to share our Annual Review of Neuroscience paper on language in brains, minds, and
machines with Nancy Kanwisher and Ev Fedorenko. Broadly, we survey the insights that
artificial language models (LMs) provide on the question of how language is represented
and processed in the human brain.
The language LM-neuroscience field is moving very fast, but I hope that this review
will serve as a useful timestamp for contextualizing the findings from this field.
In this review paper, we first ask, what are we trying to model? We discuss the human
language system as a well-defined target for modeling efforts aimed at understanding
the representations and computations underlying language (also see Fedorenko, Ivanova,
Regev, 2024). Second, we discuss what we actually want from computational models of
language: There is a trade-off between parsimony (i.e., intuitive-level understanding;
many classes of former models) and predictive accuracy (i.e., models that explain
accurately explain behavioral/neural data). LMs are data-driven, stimulus-computable
and have high accuracy, albeit at the expense of parsimony. However, if we use them
in controlled experimental settings, I will argue that we can use them to make meaningful
inferences despite their lack of inherent interpretability.
Next, we lay out arguments as to why, a priori, we would or would not expect LMs to share
similarities with the human language system. In brief, we would expect LMs to share
similarities with the human language system because of their similar behavioral language
performance (formal linguistic competence, e.g., Mahowald, Ivanova et al., 2023), both
systems are highly modulated and/or shaped by prediction, both systems are sensitive to
multiple levels of linguistic structure, and finally, ‘small’ LMs that do language well,
struggle with other tasks (e.g., simple arithmetic), suggesting that near-human language
ability does not entail near-human reasoning ability. Conversely, LMs are very different
from humans in their learning procedure, access to long-range contexts of prior input,
and of course, hardware differences.
We then describe evidence that LMs represent linguistic information similarly enough to
humans to enable relatively accurate brain encoding and decoding, and then turn to the
question: Which properties of LMs enable them to capture human responses to language?
LMs vary along many dimensions, which we separated into 3 categories: model architecture,
model behavior and model training. A few take-aways are: For architecture, contextualized
LMs provide a big improvement in brain-LM alignment over decontextualized semantic models.
However, within contextualized LMs, many architectures fit brain data well. Larger LLMs
predict brain data better, but become worse at predicting human language behavior. For
behavior, in line with the idea that neural representations are shaped by behavioral
demands, LMs’ ability to predict linguistic input is positively correlated with brain
alignment. It remains unknown whether prediction per se, or other factors such as
representational generality, is the key factor underlying alignment. Lastly, for training,
even LMs trained on a developmentally plausible amount of training data align with brain
data. Semantic properties of training data seem to matter more for brain-LM alignment
than morphosyntactic ones. Fine-tuning can increase brain-LM alignment (task- and model
dependent).
The final part of the paper discusses the general use as LMs as in silico language networks,
and we describe challenges and future directions associated with the use of LMs in
understanding more about language in the mind and brain.
Tuckute, G., Kanwisher, N., Fedorenko, E. (2024): Language in Brains, Minds, and Machines Annual Review of Neuroscience 47:277-301, doi: https://doi.org/10.1146/annurev-neuro-120623-101142 .
Review on how to optimally use neuroscience data and experiments to develop better models of the brain
How do we optimally use neuroscientific data (behavior and neural recordings) to develop better models of processes in the brain? Kohitij Kar and I organized a Generative Adversarial Collaboration (GAC) workshop during the Cognitive Computational Neuroscience (CCN) conference in 2022 (along with Dawn Finzi, Eshed Margalit, Jacob Yates, Joel Zylberberg, Alona Fyshe, SueYeon Chung, Ev Fedorenko, Niko Kriegeskorte, Kalanit Grill-Spector), and this review/opinion piece synthesized our workshop take-aways and broader thoughts on the neuro-inspired model development field.
Read moreThe review focuses on visual and language processing, and we broadly tackle two questions: i) How should we use neuroscientific data in model development (raw experimental data vs. qualitative insights)?, and ii) How should we collect experimental data for model development (model-free vs. model-based)?. We discuss the pros and cons associated with each stance, and moreover, we review how neuroscience data has traditionally been leveraged to advance model-building within the domains of vision and language. Finally, we discuss directions for both experimenters and model developers in the quest to advance artificial models of brain activity and behavior.
Tuckute, G., Finzi, D., Margalit, E., Zylberberg, J., Chung, S.Y., Fyshe, A., Fedorenko, E., Kriegeskorte, N., Yates, J., Grill-Spector, K., Kar, K. (2024): How to optimize neuroscience data utilization and experiment design for advancing primate visual and linguistic brain models? Neurons, Behavior, Data analysis, and Theory, doi: https://doi.org/10.51628/001c.127807 .
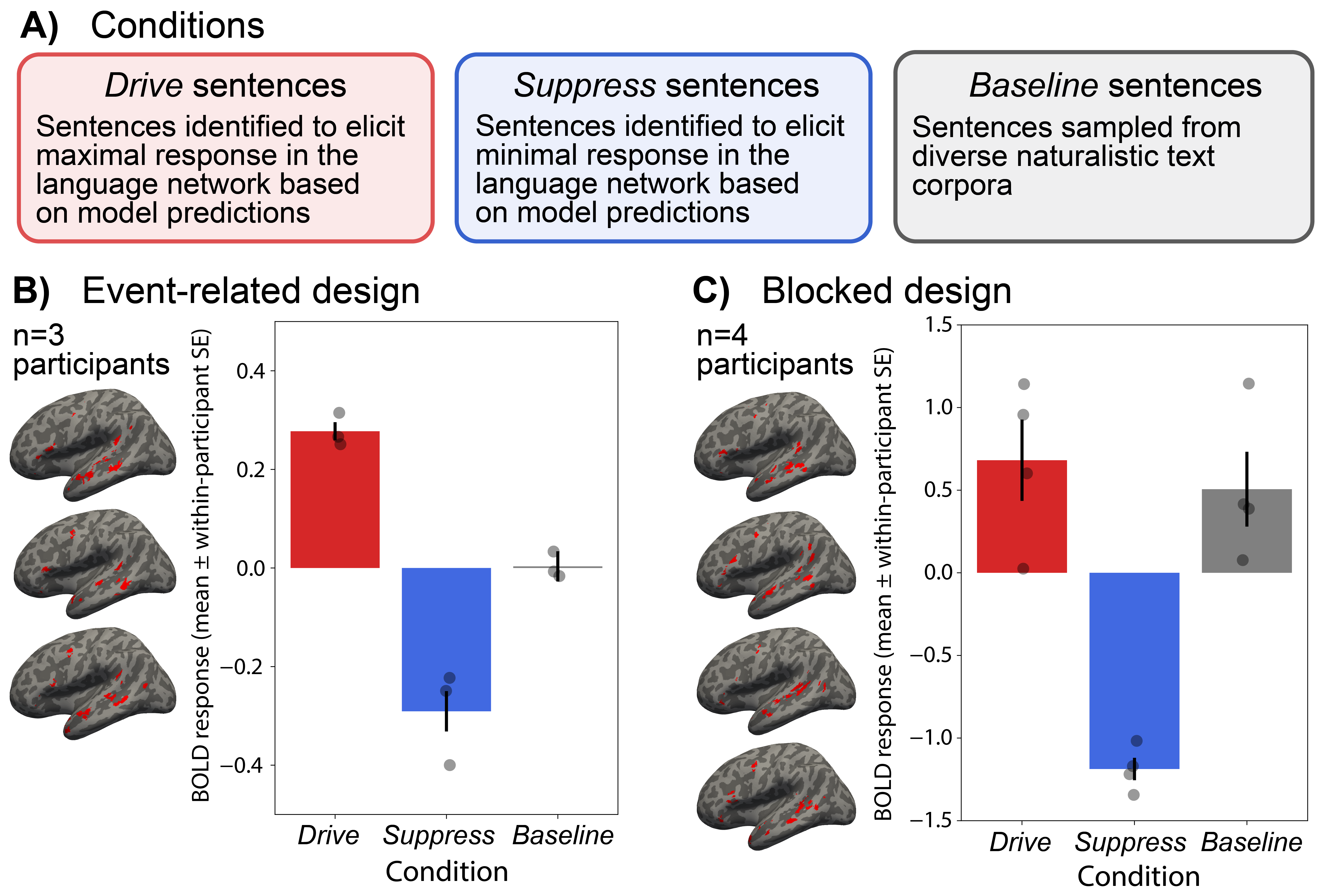
Driving and suppressing the human language network using large language models
Transformer language models are today's most accurate models of language processing in the brain (e.g., Schrimpf et al., 2021; Goldstein et al., 2022; Caucheteux et al., 2023).
However, it remains unknown whether LLM features can causally control language responses in the brain--a stronger test of model validity.
In this work, we ask two main questions: i) Can we leverage GPT language models to
drive or suppress brain responses in the human language network--a strong test of the model that
extends beyond prediction to causal neural control? ii) What is the
“preferred” stimulus of the language network, and which linguistic properties characterize those stimuli?
To answer these questions, we first developed a rapid, event-related single-sentence fMRI paradigm that enabled
us to record brain responses as participants read 1,000 linguistically diverse sentences.
Next, we fit an encoding model to predict the left hemisphere language network’s response to an arbitrary sentence from GPT2-XL embeddings.
We then used our encoding model to identify new sentences to activate the language network
maximally ("drive sentences") or minimally ("suppress sentences") by searching across a
massive number of sentences (~1.8 million).
We showed that these model-selected new sentences indeed drive and suppress the activity
of human language areas in new individuals. Hence, we trained an encoding model to
generate predictions about the magnitude of activation in the language network for the new
drive/suppress sentences and then closed the loop, so to speak, by collecting brain data
for the new sentences from new participants, effectively showing that GPT2-XL captures features related
to language processing that enables us to “control” brain activity.
Second, we wanted to understand what kinds of sentences that the language network responds
to the most. This general approach is rooted in the work by Hubel and Wiesel in the late
1950’s and 1960’s, who discovered what kinds of visual input (e.g., specific orientations of
light) that would make neurons in the visual cortex of cats and monkeys fire the most.
The core premise behind Hubel and Wiesel's approach (and ours) is that understanding what kinds
of stimuli that maximally engage a given system provides insight into the functional properties of that system.
In our study, we characterized all of our sentences (spanning the full range of brain responses
from low to high) using 11 linguistic properties (we collected a lot of behavioral ratings!).
We discovered that sentences with a certain
degree of unusual grammar and/or meaning elicit the highest activity in the language network
in the form of an inverted U-shape – for instance, sentences like
“I’m progressive and you fall right.” would elicit the highest responses. Conversely,
sentences that were highly normal/frequent (e.g., "We were sitting on the couch.")
or highly unusual, like a string of words (e.g., "LG'll obj you back suggested Git.")
would elicit quite low responses. In other words, the language network responds strongly
to sentences that are “normal” (language-like) enough to engage it, but unusual enough
to tax it. This means that specific areas of your brain – the language network – will
respond selectively to linguistic input that aligns with the statistics of the language
and will work really hard to make sense of the words and how they go together.
Taking a step back, we establish LLMs as causal tools to investigate language in the mind and brain,
with implications for future basic-science investigations and clinical research.
Tuckute, G., Sathe, A., Srikant, S., Taliaferro, M., Wang, M., Schrimpf, M., Kay, K., Fedorenko, E. (2024):
Driving and suppressing the human language network using large language models,
Nature Human Behavior, doi:
https://doi.org/10.1038/s41562-023-01783-7
.
I also wrote a
blog post about this work
for Springer Nature's "Behind the paper" series.
The associated data and analysis code can be found here.
Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions
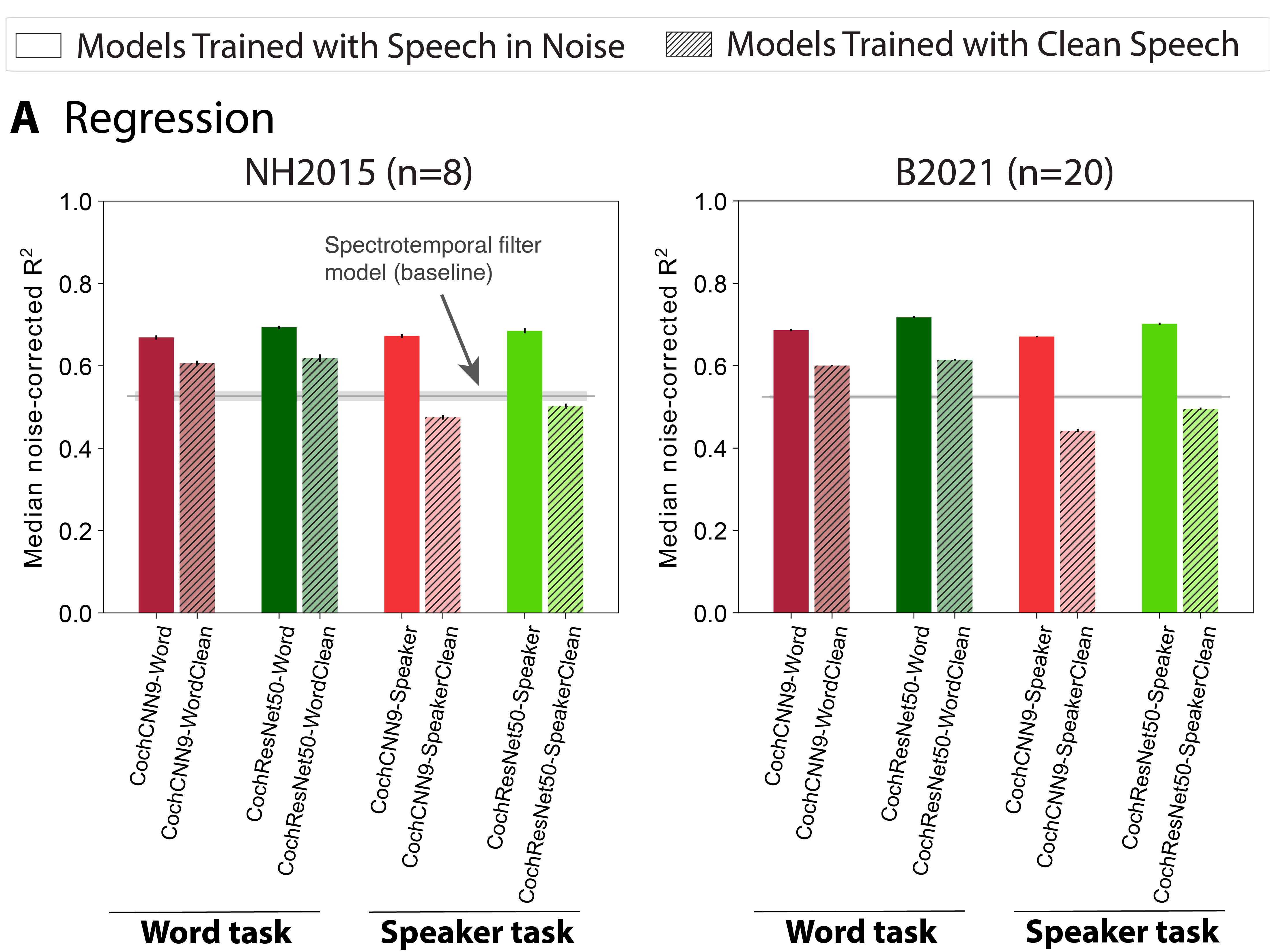
In this work, we present an extensive analysis of audio neural networks as models of auditory processing in the brain. We evaluated brain-model correspondence for 19 auditory deep neural networks (DNNs) (9 publicly available models, 10 models trained by us spanning four tasks) on two fMRI datasets (n=8, n=20) and using two different evaluation metrics (via regression and representational similarity analysis, RSA). We found that most DNNs (but not all) showed greater brain-model similarity than a traditional filter-bank model. Results were highly consistent between datasets and evaluation metrics. This brain-DNN similarity was strictly dependent on task-optimization. DNNs with permuted weights (which destroys the structure learned during model training) performed below the baseline model. Most trained DNNs exhibited correspondence with the hierarchical organization of the auditory cortex, with earlier DNN stages best matching primary auditory cortex and later stages best matching non-primary cortex.
Read more
Other three findings that are worth highlighting: i) A model’s training data significantly
influences its similarity to brain responses: models trained to perform word/speaker
recognition in the presence of background noise are much better at accounting for
auditory cortex responses than models trained in quiet. ii) A model trained on multiple
tasks was the best model of the auditory cortex overall, and also accounted for neural
tuning to speech and music. Training on particular tasks improved predictions for
specific types of tuning, with the MultiTask model getting “best of all worlds”.
iii) Finally, in light of recent discussion suggesting that the dimensionality of a model’s representation correlates with regression-based brain predictions,
we evaluated how the effective dimensionality (ED) of each network stage correlated with both the regression and RSA metrics.
There was a modest correlation between ED and brain-model similarity but significantly less than that between the two datasets or the two similarity measures.
Thus ED does not seem to explain most of the variance across DNNs in our datasets.
Finally, our work demonstrates that if the core goal is to obtain the most quantitatively
accurate model of the auditory system, machine learning models move us closer to this goal.
However, our findings also highlight the explanatory gap that remains (predictions of all
models are well below the noise ceiling), as well as the need for better model-brain
evaluation metrics and finer-grained neural recordings to better distinguish models.
Tuckute, G.*, Feather*, J., Boebinger, D., McDermott, J. (2023): Many but not all deep neural network audio models
capture brain responses and exhibit correspondence between model stages and brain regions,
PLoS Biology 21(12), doi:
https://doi.org/10.1371/journal.pbio.3002366
.
Code and data associated with the paper can be found here.
Cortical registration using anatomy and function

Brains have complex geometric anatomy and brains differ a lot across individuals. Aligning a brain to another individual or to a common atlas space is a challenging task. Traditionally, this challenge has been solved using registration of anatomical folding patterns of the cortex. However, it is known that many functional regions in the brain do not exhibit a consistent mapping onto macro‑anatomical landmarks. Hence, we might miss out on crucial information in aligning brains if we do not take function into account. In this work, we propose JOSA (Joint Spherical registration and Atlas building) that models anatomical and functional differences when aligning brains and building cortical atlases. Read more
We used functional data from a well‑validated language localizer task (e.g., Lipkin et al., 2022) for a set of 800 participants,
jointly aligning the language contrast (sentences versus strings of non‑words) with cortical folding patterns,
demonstrating better alignment in both folding patterns and function compared to two existing methods.
Li, A., Tuckute, G., Fedorenko, E., Edlow, B.L., Fischl, B., Dalca, A.V. (2024): JOSA: Joint surface-based registration and atlas construction of brain geometry and function,
Medical Image Analysis 98; doi: https://doi.org/10.1016/j.media.2024.103292.
Li, A., Tuckute, G., Fedorenko, E., Edlow, B.L., Fischl, B., Dalca, A.V. (2024): Joint cortical registration of geometry and function using semi-supervised learning,
Medical Imaging with Deep Learning, Proceedings of Machine Learning Research (PMLR) 227:862–876; doi:
https://proceedings.mlr.press/v227/li24b.
Investigating brain-model similarity using information-theoretic compression
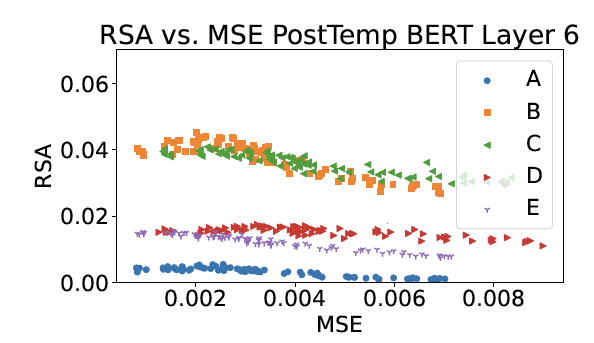
Mycal Tucker and I will be presenting a poster at NeurIPS 2023 (UniReps Workshop; Dec 15, 3‑5 pm CT) on leveraging information theoretic tools to investigate similarity between brains and large language models (LLMs). The motivation for our work stems from the observation that languages are efficient compressors -- we convey information via lossy representations (words) (e.g., Zaslavsky et al., 2018). Hence, a good model of human language processing should compress linguistic representations in ways similar to the human brain. LLMs are today’s most accurate models of human language processing, however it is unknown whether LLM representations contain similar amounts of information as the human brain.
Read more
We took an initial stab at this question, and asked i) Do brain and LLM representations contain similar amounts of information?, and ii) Can we leverage an information bottleneck approach to generate compressed representations of brain activity and better unify the representational spaces of humans and LLMs during language processing?
Our prelimary results show that compressing brain activity in frontal language regions improves alignment with LLMs, suggesting that frontal regions in the human brain encode information that LLMs do not. There was no benefit to compressing temporal brain regions, suggesting that these regions might align better with the information present in current LLMs. Broadly, our work establishes the use of information theoretic tools as a "dial" to modify representational complexity and to better unify representational spaces, including those from biological and artificial lanuage processing.
The extended abstract can be found here: Tucker*, M. & Tuckute*, G., Increasing Brain‑LLM Alignment via Information‑Theoretic Compression, 37th Conference on Neural Information Processing Systems (NeurIPS 2023), UniReps Workshop.
Lexical semantic content, not syntactic structure, is the main contributor to LLM-brain similarity of fMRI responses in the language network

Many studies have now established that large language models (LLMs) are predictive of human brain responses during language processing.
Excited about our work that asks why and which aspects of the linguistic stimulus that contribute to LLM‑brain similarity.
To answer these questions, we used an fMRI dataset of brain responses to n = 627 diverse English sentences (Pereira et al., 2018)
and systematically manipulated the stimuli for which LLM representations were extracted.
We then fitted standard encoding model to predict brain activity from the LLM representations of these perturbed stimuli,
and evaluated the resulting predictivity performance.
Critically, we found that the lexical‑semantic content of the sentence rather than the sentence’s syntactic form
is primarily responsible for the LLM‑to‑brain similarity.
This means that manipulations that remove the content words or alter the meaning of the sentence decrease brain predictivity.
Conversely, manipulations that remove function words or perturb the syntactic structure of the sentence (e.g., by shuffling the word order)
do not lead to large decreases in brain predictivity.
We show that stimulus manipulations that adversely affect brain predictivity have two interpretable causes:
i) they lead to more divergent representations in the LLM’s embedding space (relative to the representations of the original stimuli),
and decrease the LLM’s ability to predict upcoming tokens in those stimuli.
So, stimuli that are less predictable on average lead to larger decreases in brain predictivity performance.
In summary, the critical result—that lexical‑semantic content is the main contributor to the similarity between
LLM representations and neural ones—aligns with the idea that the goal of the human language system is to extract
meaning from linguistic strings. Finally, this work highlights the strength of systematic experimental manipulations
for evaluating how close we are to accurate and generalizable models of the human language network.
Kauf*, C., Tuckute*, G., Levy, R., Andreas, J., Fedorenko, E. (2023): Lexical semantic content, not syntactic structure, is the main contributor to ANN‑brain similarity of fMRI responses in the language network, Neurobiology of Language 5(1), doi: https://doi.org/10.1162/nol_a_00116. The code associated with the project can be found here.
Frontal language areas do not emerge in the absence of temporal language areas
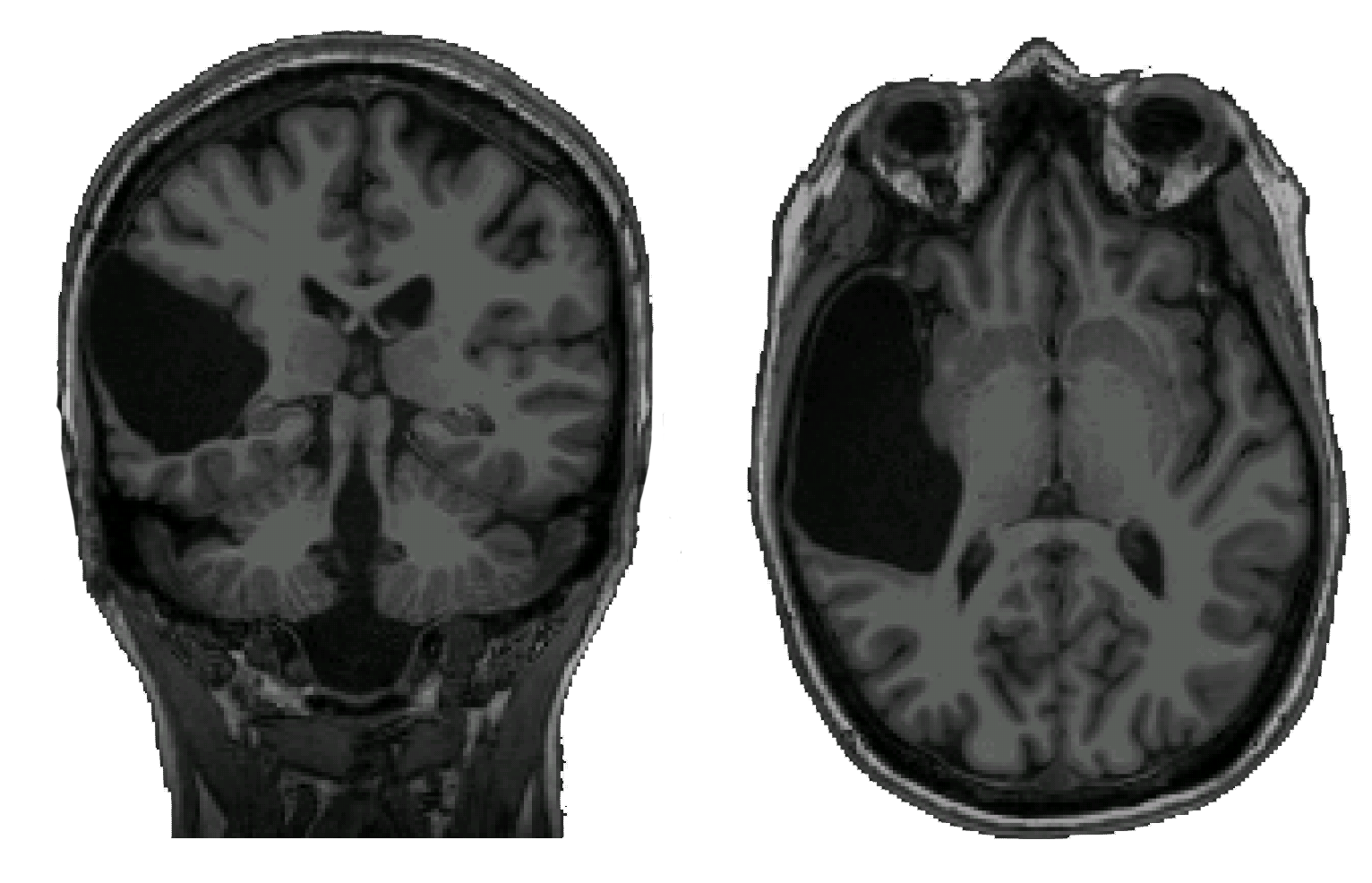
High-level language processing is supported by a left-lateralized fronto-temporal brain network. How the language network emerges and develops remains poorly understood. An important contributing factor is the difficulty of probing the functional organization of children’s brains between 1 and 3 years of age. In this study, we turn to a unique case study of an individual (EG) who was born without a left temporal lobe (but has neurotypical language abilities!). Our main question was whether frontal language areas emerge in the absence of temporal language areas.
Read more
We used fMRI methods to establish that the right hemisphere language network is similar to the left hemisphere language network in controls.
However, the critical question was whether EG’s intact left lateral frontal lobe contained language-responsive areas.
We found no reliable response to language in EG’s intact left frontal lobe, suggesting that the existence of temporal language areas
appears to be a prerequisite for the emergence of language areas in the frontal lobe.
Tuckute, G., Paunov, A., Kean, H., Small, H., Mineroff, Z., Blank, I., and Fedorenko, E. (2022):
Frontal language areas do not emerge in the absence of temporal language areas: A case study of an individual born without a left temporal lobe,
Neuropsychologia 169; doi:
https://doi.org/10.1016/j.neuropsychologia.2022.108184
.
The data and analysis code associated with the paper can be found here.
LanA (Language Atlas): A probabilistic atlas for the language network based on fMRI data from >800 individuals

This work is a massive effort (14 years of data collection!) in collaboration with Benjamin Lipkin (lead), Ev Fedorenko, and a bunch of brilliant current/former lab members of EvLab. Given any location in the brain, what is the probability of that particular location being selective to language? We present a probabilistic language atlas (LanA) that allows to answer exactly this question. For any 3D pixel (voxel/vertex) in the volumetric or surface brain coordinate spaces, how likely is that pixel to fall within the language network?
Read more
The atlas was obtained from >800 individuals based on functional localization (a contrast between processing of sentences and a linguistically/acoustically degraded condition, such as non-word strings).
Thus, among these ~800 individuals, we provide a group average map that allows us to quantify and visualize where ‘the average’ language network resides.
Examples of use cases of LanA are: 1) A common reference frame for analyzing group-level activation peaks from past/future fMRI studies,
2) Lesion locations in individual brains, 3) Electrode locations in intracranial ECoG/SEEG investigations,
4) Functional mapping during brain surgery when fMRI is not possible, and others.
The atlas is openly available, alongside individual contrast/significance maps and demographic data.
Lipkin, B.*, Tuckute, G., Affourtit, J., Small, H., Mineroff, Z., Kean, H., Jouravlev, O., Rakocevic, L., Pritchett, B., Siegelman, M., Hoeflin, C., Pongos, A., Blank, I., Shruhl, M.K., Ivanova, A., Shannon, S., Sathe, A., Hoffmann, M., Nieto-Castañón, A., Fedorenko, E. (2022):
LanA (Language Atlas): Probabilistic atlas for the language network based on precision fMRI data from >800 individuals.
Scientific Data 9, 529;
doi: https://doi.org/10.1038/s41597-022-01645-3.
The atlas and visualizations are hosted at
http://evlabwebapps.mit.edu/langatlas/.
SentSpace: Large-scale benchmarking and evaluation of text using cognitively motivated lexical, syntactic, and semantic features

Imagine you want to quantify a sentence using a large set of interpretable features. Maybe you are interested in obtaining features that relate to the sentiment of the sentence, maybe features that are known to cause language processing difficulty (such as frequency or age of acquisition). With SentSpace, we introduce such system: we enable streamlined evaluation of any textual input. SentSpace characterizes textual input using diverse lexical, syntactic, and semantic features derived from corpora and psycholinguistic experiments. These features fall into two main domains (sentence spaces, hence the name): lexical and contextual.
Read more
Lexical features operate on individual lexical items (words) and entail features such as concreteness, age of acquisition,
lexical decision latency, and contextual diversity.
As several properties of a sentence cannot be attributed to individual words,
so the contextual module quantifies a sentence as a whole. This module entails features such as syntactic storage
and integration cost, center embedding depth, and sentiment. Hence, SentSpace provides an interpretable sentence
embedding with features that have been to shown to affect language processing.
SentSpace allows for quantification and comparison of different types of text and can be useful for answering
questions like: How does text generated by an artificial language model compare to that of humans?
How does utterances produced by neurotypicals compare to that of individuals with communication disorders?
What psycholinguistic information do high-dimensional vector representations from artificial language models capture?
Tuckute, G.*, Sathe, A.*, Wang, M., Yoder, H., Shain, C., Fedorenko, E. (2022):
SentSpace: Large-scale benchmarking and evaluation of text using cognitively motivated lexical, syntactic, and semantic features.
NAACL System Demonstrations.
https://aclanthology.org/2022.naacl-demo.11/.
SentSpace Python package: sentspace.github.io/sentspace
Can we use transformer models to drive language regions in the brain?

I gave an informal poster presentation at the Boston/Cambridge CogSci 2021 meet-up on exploiting transformer language models to drive regions in the human brain. I presented ideas and preliminary data on whether and how that is feasible, and if so, what we can learn from it. Our preliminary analyses show promising results, with transformer-selected stimuli driving responses in language regions compared to baselines. This is ongoing work with Christina (Mingye) Wang, Elizabeth Lee, Martin Schrimpf, Noga Zaslavsky, and Ev Fedorenko. More soon!
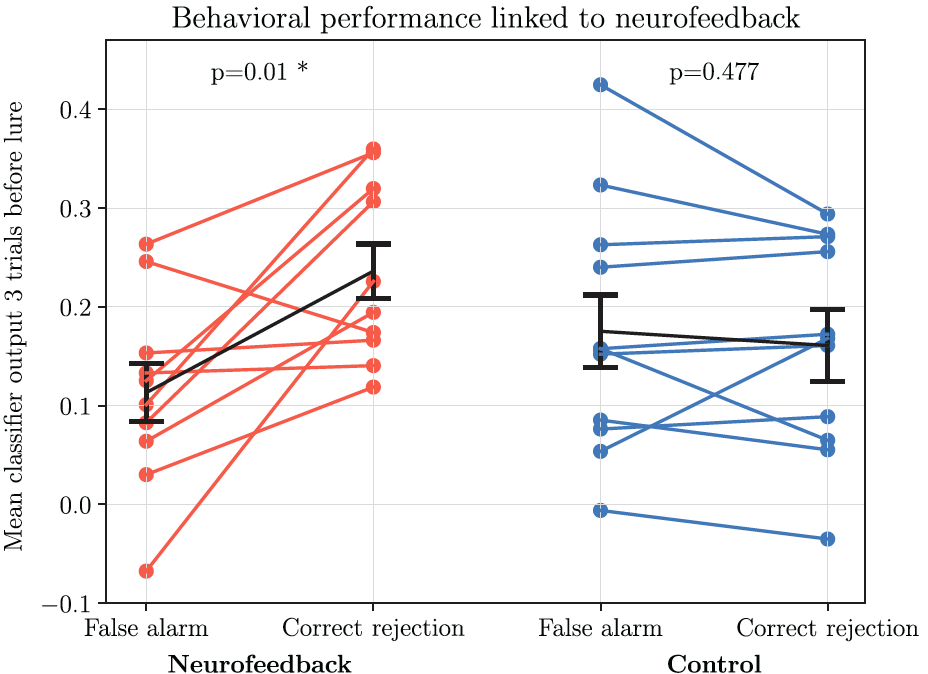
Real-time decoding of visual attention using closed-loop EEG neurofeedback
Happy to share that my MSc thesis work from DTU is now published! Neurofeedback is a powerful tool for linking neural states to behavior. In this project, we asked i) Whether we can decode covert states of visual attention using a closed-loop EEG system, and ii) If a single neurofeedback training session can improve sustained attention abilities.
Read more
We implemented an attention training paradigm designed by DeBettencourt et al., (2015) in EEG.
In a double-blinded design, we trained twenty-two participants on the attention paradigm within a single neurofeedback
session with behavioral pretraining and posttraining sessions.
We demonstrate that we are able to decode covert visual attention in real time.
First of all, we report a mean classifier decoding error rate of 34.3% (chance = 50%).
Second, we link this decoding performance to behavioral states, and show that within the neurofeedback group,
there was a greater level of task-relevant attentional information decoded in the participant's brain before
making a correct behavioral response than before an incorrect response (not evident in the control group; interaction p=7.23e−4).
This indicates that we were able to achieve a meaningful measure of subjective attentional state in real time
and control participants' behavior during the neurofeedback session.
Finally, we do not provide conclusive evidence whether a single neurofeedback session per se provided lasting effects in sustained attention abilities.
Tuckute, G., Hansen, S.T., Kjaer, T.W., Hansen, L.K. (2021): Real-Time Decoding of Attentional States Using Closed-Loop EEG Neurofeedback,
Neural Computation 33(4),
doi: https://doi.org/10.1162/neco_a_01363.
A video of the neurofeedback system is available here.
Code and sample data are on GitHub.
Biological closed-loop feedback preserves proprioceptive sensorimotor signaling
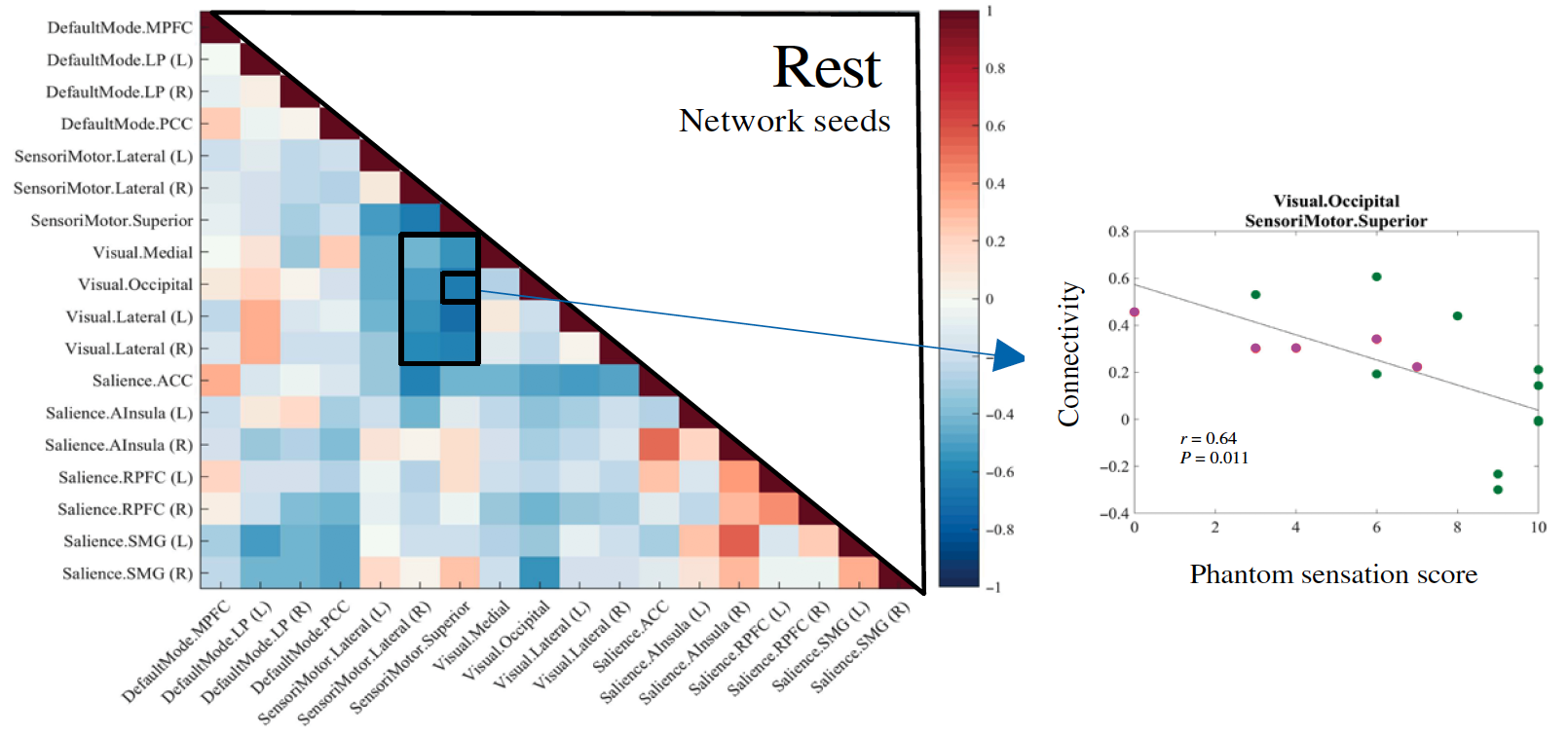
The brain undergoes marked changes in function after limb loss and amputation. In this work, we investigate individuals with a traditional lower limb amputation, no amputation and a novel amputation procedure that preserves physiological central-peripheral signaling mechanisms. We demonstrate that the proprioceptive signaling enabled by the novel amputation procedure restores sensorimotor feedback in the brain. We investigate changes in functional connectivity in the brain, and show that the lack of proprioceptive feedback results in a strong coupling between visual and sensorimotor networks.
Read moreThis finding suggests a heavy reliance on visual information when no sensory feedback is available, possibly as a compensatory mechanism. Conclusively, we demonstrate that closed-loop proprioceptive feedback can enable desired neuroplastic changes toward improved neuroprosthetic capability.
Srinivasan, S.S., Tuckute, G., Zou, J., Gutierrez-Arango, S., Song, H., Barry, R.L., Herr, H. (2020): AMI Amputation Preserves Proprioceptive Sensorimotor Neurophysiology, Science Translational Medicine, Vol. 12, Issue 573; doi: 10.1126/scitranslmed.abc5926.
Artificial neural networks accurately predict language processing in the brain
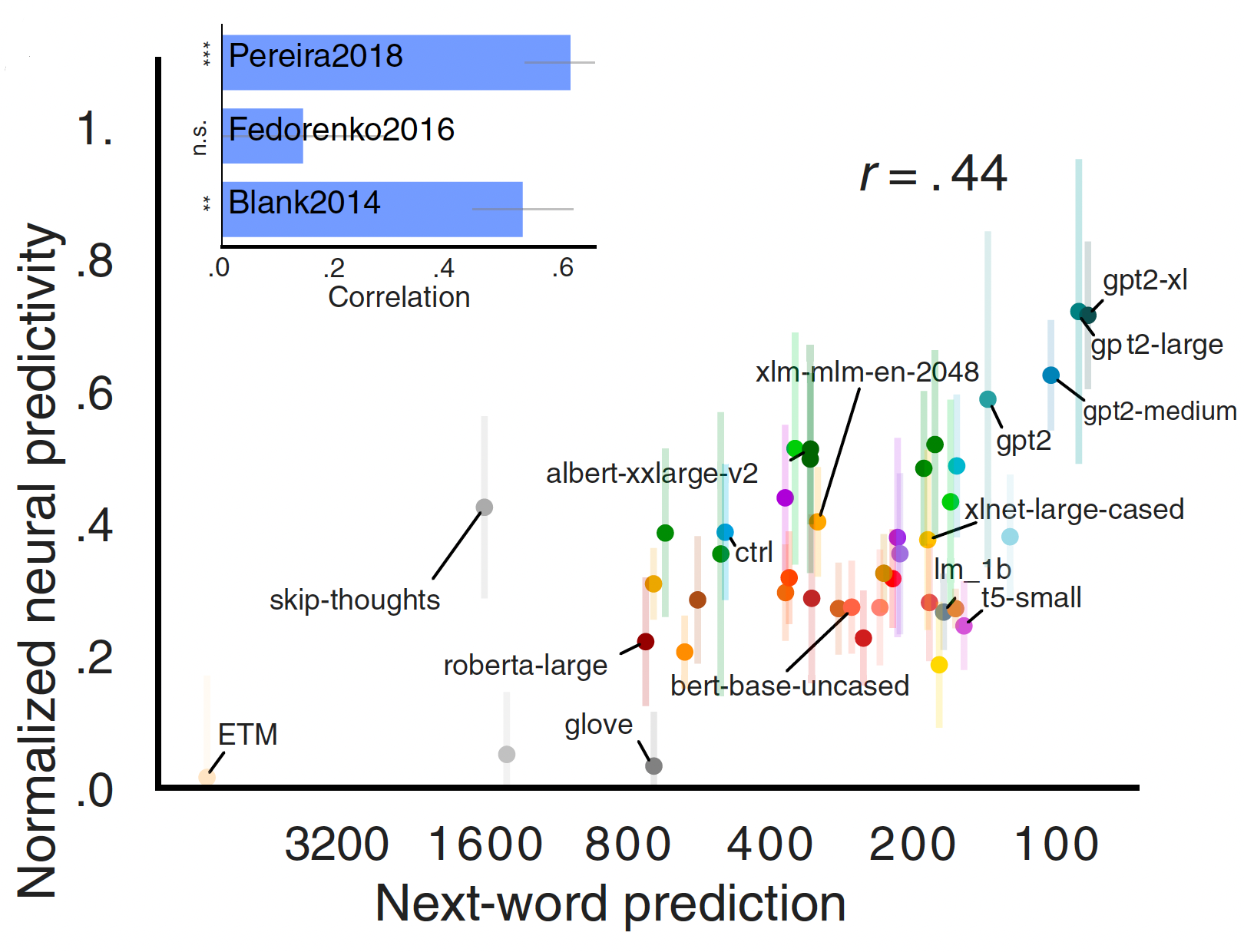
In the recent years, great progress has been made in modeling sensory systems with artificial neural networks (ANNs) to move towards mechanistic accounts of brain processing. In this work, we investigate if we can exploit ANNs to inform us about higher level cognitive functions in the human brain -- specifically, language processing. Here, we ask which language models best capture human neural (fMRI/ECoG) and behavioral responses. Moreover, we investigate how this alignment links to computational accounts of predictive processing. Lastly, we examine the contributions of intrinsic model network architecture in brain predictivity. We tested 43 diverse state-of-the-art language models spanning a diverse set of embedding, recurrent, and transformer models. In brief, certain transformer families (GPT2) demonstrate consistent high predictivity across all neural datasets investigated. These models’ performance on neural data correlate with language modeling performance (next-word prediction), but not other (the General Language Understanding Evaluation; GLUE) benchmarks, suggesting that a drive to predict future inputs may shape human language processing.
Read more
I think these two points open up for multiple exciting research questions: Given that better-performing models are more brain-like,
how can we engineer more brain-inspired models? Most state-of-the-art language models are inefficient (requiring billions of
parameters and training samples resulting in massive energy expenditure),
not robust (can be fooled by adversarial input), and not very interpretable (making it challenging to localize causes of success/unwanted capabilities).
How can we exploit principles from the human brain that allows us to processes language efficiently and robustly?
Can we modularize or constrain language model representations using human data? In which scenarios do interpretability
and performance go hand in hand?
Schrimpf, M., Blank, I.*, Tuckute, G.*, Kauf, C.*, Hosseini, E.A., Kanwisher, N., Tenenbaum, J., Fedorenko, E. (2021):
The neural architecture of language: Integrative modeling converges on predictive processing.
PNAS, 118(45):
https://doi.org/10.1073/pnas.2105646118.
Oral presentation at Society for the Neurobiology of Language (SNL) 2020 in October (SNL 2020 Merit Award Honorable Mention).
The code and data associated with the project can be found here
(updated Brain-Score Language here).